
New challenges constantly affect space safety, mainly due to the complex technological, and procedural evolution of recent years. Current socio-technical systems are inherently complex. Non-linear interactions and tight couplings among components (mechanical parts, human operators, control actors, operations procedures, etc.) make the traditional linear thinking and the intent to look for a static cause-effect relationship potentially inadequate for reliable assessments.
The methods and models used to explain and analyse accidents or assess risks have evolved over years. New ones have been developed to cope with “new” types of accidents or to adapt to the evolutions in technology. Human factors started to be considered after the Three Mile Island accident in 1979 and organizational methods after Challenger and Chernobyl, both in 1986. Today, however, a new perspective on safety assessment methods gains a primary interest: systemic methods. These acknowledge the relevance of considering the system as a whole, following a new perspective on safety management, the so-called Safety-II.
Safety-II acknowledges that systems are incompletely understood, that descriptions can be complicated and that changes are frequent and irregular rather than infrequent and regular, i.e. systems are intractable. These concepts are totally opposed to the decomposability and bi-modality of traditional safety assessment reasoning, the so-called Safety-I. In many current systems, decomposition is not always meaningful, system functioning is not bimodal (success/failure) but flexible and variable, and even though some outcome can be interpreted as a linear consequences of other events, some event emerge as couplings in terms performance variability.
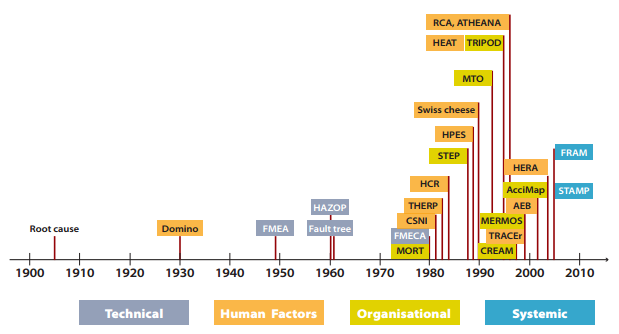
Evolution of accident analysis and risk assessment methods and models. credits – eurocontrol
Dynamic Safety for a Space Mission
Furthermore, a system is continuously evolving, dependant on the environment and responding to external and internal disturbances, i.e. economic, workload and safety pressures. Thus, a system could lie within the safety boundaries only if it has the potential to react promptly to external and internal disturbances, even if it is inherently complex. This represents the so-called dynamic safety model and, as expectable, completely fits a generic space mission needs. The aim is to improve understanding of system functioning and making it resilient to enhance its safety level.
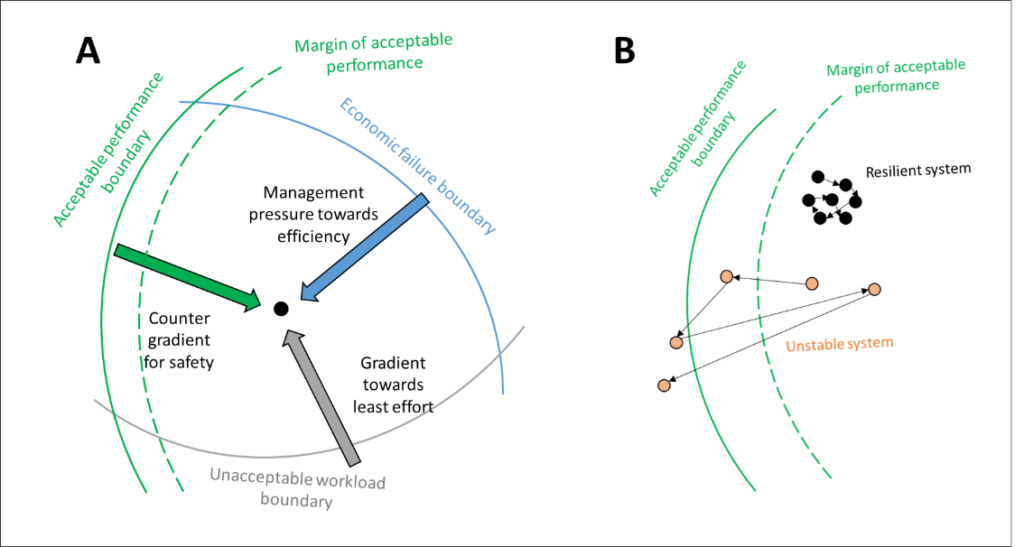
Adapted version of Cook and Rasmussen’s dynamic safety model. credits – Cook R, Rasmussen J
Dynamic Systemic Safety: the FRAM
A potential path to enhance safety may consist of developing a systemic method, which allows acknowledging internal and external dynamic complexity. The Functional Resonance Analysis Method (FRAM), developed by professor Erik Hollnagel, recognizes the importance of paying attention both to “things that go wrong” and “things that go right”. FRAM therefore aims to describe how things happen rather than consider only the linear aetiology of a failure. This core concept recognizes the limits of decomposition and causality, in favour of a more complex principle, called functional resonance. It is therefore more important to understand system dynamics and performance variability rather than modelling individual technological, human or organization failures. FRAM permits thus considering inter-related patterns of events rather than simple causal sequences, enhancing traditional safety assessment techniques.
FRAM functions aim to describe everyday system’s functioning, not simply individual activities of each component. A FRAM function represents the activities required to produce a certain outcome, through six different aspects:
Input (I): that which is used or transformed to produce the output.
Output (O): that which is produced by the function. It can be either an entity or a state change and constitutes links to subsequent functions. Precondition (P): system conditions that must be fulfilled before the function can be carried out.
Resource (R): that which is needed or consumed by the function to process input (e.g. matter, energy, hardware, software, and operators).
Control (C): that which supervises or adjust a function. It can be plans, procedures or guidelines.
Time (T): temporal constraints of the function, with regard to both duration and time of execution.
The six aspects are traditionally placed at the corners of a hexagon, which represents the function.
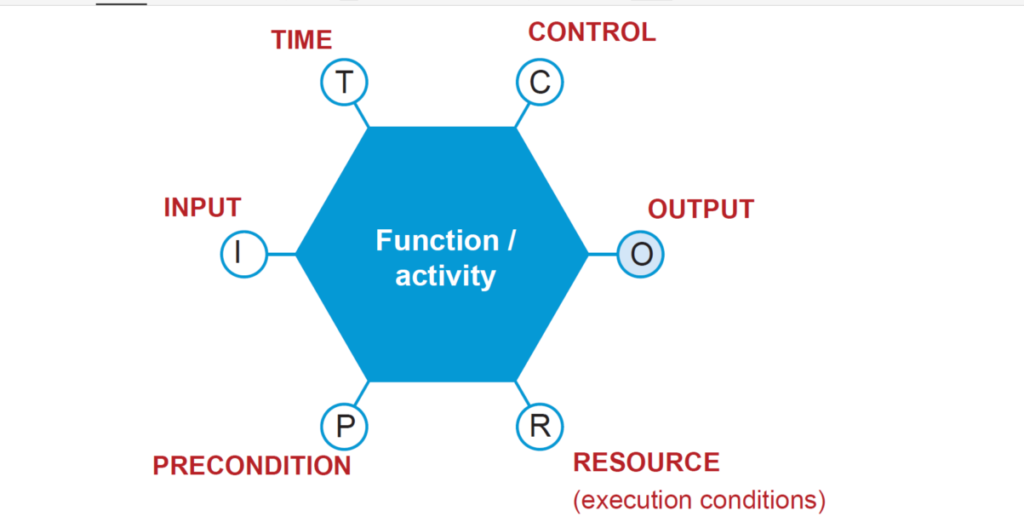
Graphical representation of a FRAM function
The traditional FRAM relies on four principles:
Equivalence of failures and successes. Failure and successes both arise from everyday work variability, which allows both things go right, working as they are imagined to do, and things go wrong. This latter is possible due either to a single system component failure or to a system failure with no single cause recognisable.
Principle of approximate adjustments. According to the specific situation, people as individuals or as a group and organizations adjust their work, modifying their everyday performance to match the partly intractable and underspecified working conditions of the large-scale socio-technical systems.
Principle of emergence. This principle acknowledges that it is not ever possible to identify the aetiology of a specific safety event or risk. In this context, an event is emergent, as opposed to traditional resultant events. The emergency is due to specific combinations of time and space conditions, which can lead to unwanted and unpredictable events. Furthermore, these events’ combinations may be transient and hidden, not leaving any traces.
Functional resonance. The functional resonance represents the detectable signal emerging from the unintended interaction of the normal variabilities of multiple signals. This resonance is not completely stochastic, because the signals variability is not completely random but it is subject to certain regularities, i.e. recognizable short cut or heuristic, that characterize different types of functions as shown below.
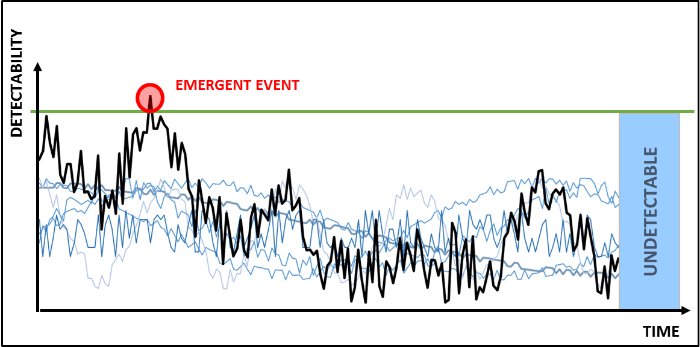
Example of functional resonance (the black line) arising from multiple signals (the blue lines).
Evolving FRAM for Space Missions’ Needs
Understanding performance variability is a crucial point of a FRAM analysis. Performance variability describes how functions can couple and how this can lead to unexpected outcomes. For this purpose, it is mandatory to describe it accurately.
Currently, FRAM is a qualitative description of system function, allowing a logic and linguistic analysis of work-as-done and variability of everyday work. In line with the traditional FRAM approach, it is possible to define performance variability through its different manifestations: the so-called phenotypes (PH), i.e. speed, distance, sequence, object, force, duration, direction, timing. The evolution proposed here consists of defining specific rule blocks based on IF-THEN logic. The first one, the PRB (Phenotypes Rule Block) allows combining the variability in terms of each phenotype for each j-th output, where PH=1, 2,…6, in order to obtain the Output Variability. Furthermore, it is necessary to consider how the output affects related functions. The damping/amplification factor describes these effects and by the CRB (Coupling Rule Block) it is possible to obtain a synthetic index, which addresses how critical is each coupling, i.e. the Variability Priority Number.
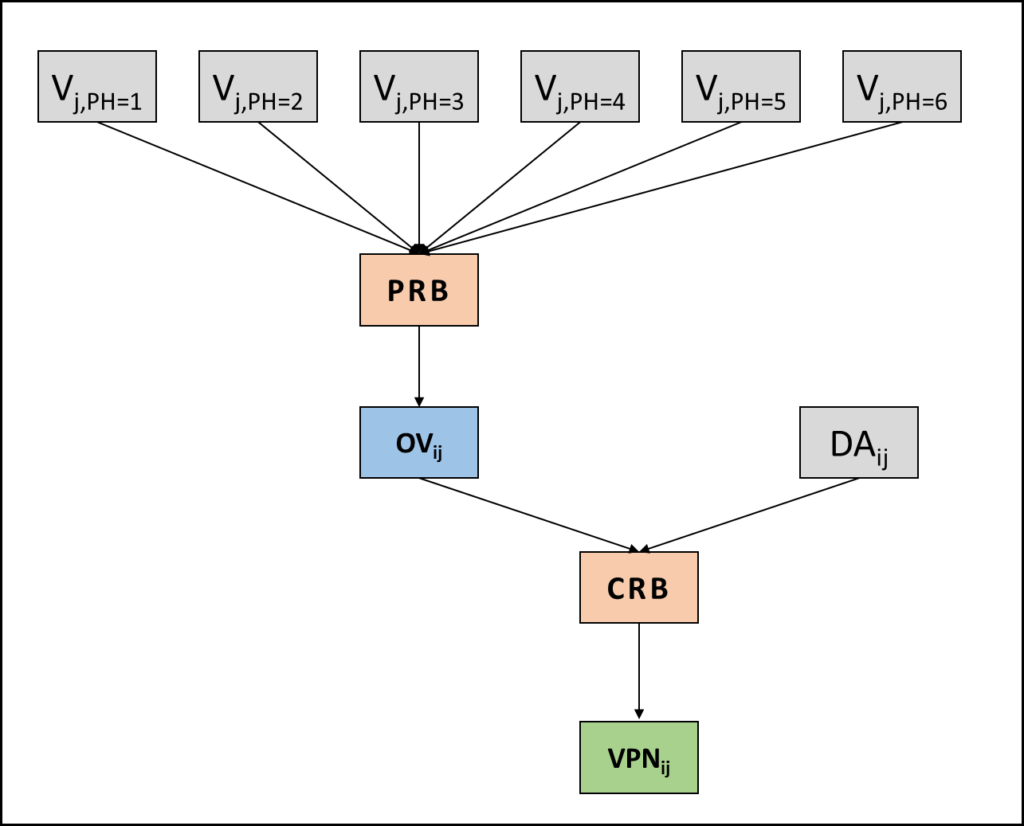
Input and output of Phenotypes Rule Block and Coupling Rule Block
In an operational context, the main problem at defining the variability scores arises from the awareness that a static behaviour for any complex system component usually does not reflect its real functioning. For example, even though an instrument with a low failure rate generates a generally nominal output, it may have rare errors that cause potential delays on transmissions, resulting thus in a late or imprecise output (based on the relative phenotypes). This idea acquires an even more relevant role for organizational and human functions, due to the more unpredictable effects in everyday work.
Defining a static variability score may lead to erroneously results and biased analyses: variability cannot be represented by a static numeric score but rather it requires a distribution. For example, technical datasheet, past reports, data from simulation tests and crew resource management, may help to draw in detail the variability of each function and thus the distributions. That is the reason for adopting Monte Carlo simulation to evaluate multiple combinations of performance variability and their effect on the output, once assigned the variability in terms of each phenotype.
Once defined the map and the variability, it is possible to identify the more critical couplings, analysing their distribution. The higher the score, the higher the criticality of that coupling, or more specifically, the higher the cumulative distribution over a threshold, the higher the criticality. A preliminary case study based on Apollo power descent confirms early results of the method. Firstly, the analysis defines the traditional map of FRAM (the FRAM model) for the process, built based on Apollo Flight journal and MSC Internal Note NO. S-PA-8N-021 A. The model looks quite tricky to read, but it describes the system’s functioning and highlights tight and often hidden couplings among functions: reducing complexity is not always the right way to understand complexity itself!
However, the final steps of the evolved FRAM proposed here, allows isolating critical couplings and defining where the functional resonance may lead to unexpected outcomes. An example of some critical couplings linked together to constitute a critical path is shown below. It depicts the critical role of propellant (and a reliable verification of its level) to achieve a safe landing, in relation to the telemetry to ground and communication between the crew and MCC-H. Besides the technical failure of lights, it is also necessary to consider the importance of the limits on the gauges of fuel.
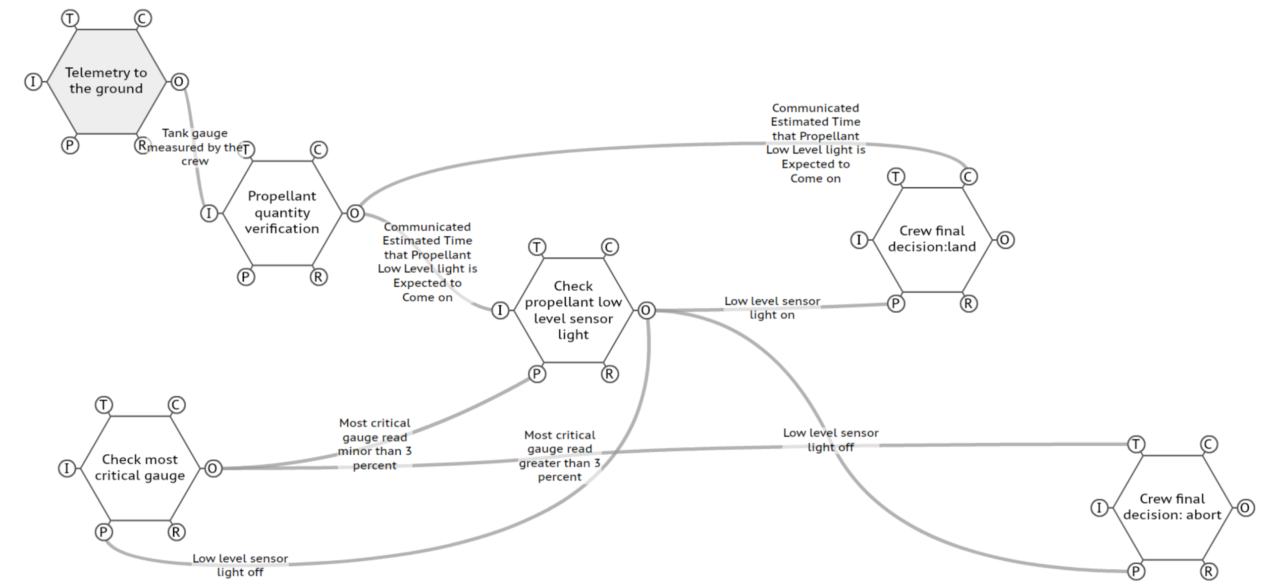
An example of a FRAM critical path
Conclusion
FRAM allows a structured analysis of a complex system where complexity arises from transient cause-effect links and non-linear interactions among agents. Although the case study in this paper is based on raw data, it depicts the possibility to highlight different risk sources at organizational, human and technological level, (e.g.) training, human factors, emergency procedure effectiveness, budget and schedule pressure, requirements definition and validation, critical system redundancy, system components’ failure.
Further research based on this approach will confirm the potential of the method, especially in case of a reliable dataset of simulation tests, technical data and operating procedures to obtain distributions more detailed. For its structure and formulation, it would be also possible to combine it as a part of the well-established Probabilistic Risk Assessment (PRA).
This article was written by Riccardo Patriarca, based on a paper presented at the 8th IAASS Conference “Safety First, Safety for All”, co-authored with Francesco Costantino and Giulio Di Gravio. Riccardo is one of the winners of the 2016 IAASS and Space Generation Advisory Council scholarships.




























![A trajectory analysis that used a computational fluid dynamics approach to determine the likely position and velocity histories of the foam (Credits: NASA Ref [1] p61).](https://www.spacesafetymagazine.com/wp-content/uploads/2014/05/fluid-dynamics-trajectory-analysis-50x50.jpg)



Leave a Reply